
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 라곰프레임워크
- 설치
- 썬
- svn
- 차이점
- 폴안티스파이앱
- 한강 #야경 #한강야경
- 라곰
- windows vista
- 스파이앱
- CVS
- Subversion
- Lambda Expressions
- volatile
- selenium #scraping #webscraping #jsoup #firefox
- 윈도우즈 비스타
- 책상
- 폴-안티
- 모니터
- 정통춘천닭갈비
- 폴-안티 스파이앱
- TortoiseSVN
- 스포티지r 풀체인지
- java8 람다식
- 폴-안티스파이앱
- lagom framework
- 폴안티
- lagom
- 폴안티 스파이앱
- 명주
- Today
- Total
장발의 개발러
Hadoop과 MongoDB를 이용한 로그분석시스템 구축사례 본문
출처: http://woochuli.blog.me/100151749978
여러분이 개발자 또는 DBA라면, 운영자와 기획자에게 "통계를 추출해 주세요" 라고 요구 사항을 받았을 때, 까다롭고 고민스러우셨을 텐데요. 이렇게 가시와 같은 통계 추출에 관하여 여러분께 명쾌한 사례와 함께 해법을 알려주실 분, 바로 NHN Technology Services의 웹서비스개발실 이정현실장님을 만나보았습니다. 몇 백만 row 이하의 소규모 데이터이거나, 통계를 추출하는 것을 전담할 수 있는 백업DB가 있다면 그나마 쉬운 고민이겠지만, 그러지 않은 상황이라면 해결을 위한 해법을 찾기가 쉽지 않을 것이라고 운을 띄우시며, 실장님께서 담당하고 있는 시스템의 통계도 이와 같은 고민에서 출발해 얻은 MongoDB와 Hadoop이라는 해결책을 여러분께 공유해 주신다고 하는데요. 이 여정에서의 고민, 접근 방법과 결론을 들어보실까요.

들어가며
우리 팀에서 개발 및 운영하고 있는 시스템의 RDBMS 스토리지 용량은 20TB이다. 이 스토리지에는 최근 6개월간 네이버 포털 서비스에서 발생하는 오브젝트 메타데이터와 그에 대한 변경 로그데이터가 저장되어 있다. 이 데이터를 서비스하기 위해 128GB 메모리의 RDBMS 장비 3대가 투입되어 있다. 그럼에도 우리의 RDBMS 상황은 시간이 지날수록 어려워지고 있다. 데이터 증가를 고려하여 최근 6개월치를 저장한다 해도 그 누적된 양이 지속적으로 증가하기 때문이다. 게다가 RDBMS 스토리지 비용 역시 만만치 않게 비싸다. 아래의 표 1과 그림 1은 우리 시스템이 사용하는 스토리지 사용 현황과 월별 사용량 추이이다.
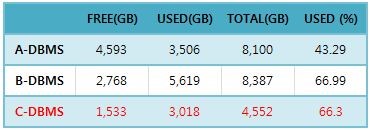
표 1. 스토리지 사용현황
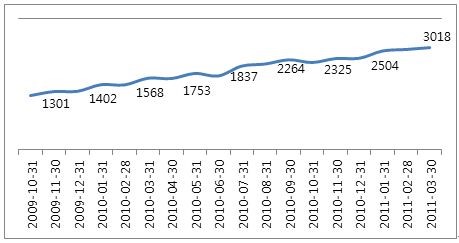
그림 1. 표 1의 C-DBMS 스토리지 사용량 추이
이 같은 상황에서 RDBMS가 아닌 다른 대안을 고민하기 시작한 가장 직접적인 원인은 최근 진행하고 있는 프로젝트의 요구사항이다. 비즈니스적인 내용을 빼고 핵심적인 부분만 정리하면 다음과 같다.
▶요구사항 1: 기존의 로그 데이터를 활용하여 지표를 추출한다.
- 요구사항 1-1: 지표 추출 주기는 최소 1일 1회 이상이어야 한다.
▶요구사항 2: 추출된 지표는 OLTP 환경으로 서비스 되어야 한다.
- 요구사항 2-1: 기존에 사용하던 시스템에 추가 조회 기능으로 추가되어야 한다.
요구사항 1은 한마디로 요약하면, “통계성격의 데이터로 지표를 가능한 빠르게 추출해 주세요”이다. 기존의 통계 데이터 추출은 개발자가 SQL을 작성한 후, DBA에게 전달하여 DBA가 검수 및 수행 후 결과를 전달하는 방식으로 진행하였다. 이런 방식으로는 “가능한 빠르게” 추출하는 것이 불가능하다. 요구사항 2는 웹 브라우저에서 지표 데이터를 조회할 수 있게 데이터를 제공해 달라는 것이다. 데이터의 양이 많지 않다면 문제가 되지 않겠지만, 예상되는 분석대상 데이터의 양이 무려 4TB에 달해서 기존의 RDBMS에 추가하기에는 여러모로 부담이 되었다. 특히 메타데이터 및 로그데이터가 지속적으로 증가하고 있어 지표 데이터까지 추가될 경우 스토리지 부담은 계속 늘어날 수 밖에 없는 상황이다.
MapReduce를 활용한 데이터 집계와 추출
요구사항에서 필요한 지표 추출용 테이블은 30~60개의 컬럼으로 구성된 일반적인 로그테이블의 형태이다. 마스터 테이블과 업무적으로 관계는 있으나, 물리적 관계는 없는 단순한 스키마이다. 따라서, 요구사항 1을 만족시키기 위한 방법은 “누구나 다 예측”가능하듯이, DBMS를 활용하거나MapReduce 기법을 활용하는 것이다. 1차로 현재의 RDBMS에서 직접 SQL을 수행하여 지표 추출을 시도했다. 이미 다양한 통계 데이터 제공을 위해 수십 개의 PL/SQL과 집계테이블이 존재하는 상황에서 쿼리를 추가하는 것은 성능만 문제 없다면 가장 간단한 해결 방법이 된다(물론 스토리지 비용은 발생하겠지만). 이를 위해 날짜를 잘게 쪼개어 분할정복법(divide-and-conquer)으로 SQL을 작성하고 진행하였다. 테스트베드를 시작하고 1주일이 지난 시점에 DBA로부터 연락이 왔다. 출근해 보니 14시간 동안 SQL문이 실행되고 있고 CPU 사용량이 평소 30~40%에서 60%로 증가하여 프로세스를 종료했다는 얘기와 함께 더 이상 테스트를 진행하기 어렵겠다는 내용이었다. 혹시나 하는 생각에 시도한 1차 지표 추출 시도는 무참하게 실패하였다. 참고로 아래 코드 1은 유사한 통계 작업에서 실제로 활용하고 있는 SQL의 일부 예이다.
INSERT INTO kpi_total_xxxxxx (dd, td,... )
SELECT /*+ index(b MSTR_CATE_PK) */
SBUSTR(v_start_datehour, 1, 8) dd, a.td,... SUM(cnt) as cnt,...
FROM (SELECT /*+ parallel_index(cm 3) index_ss(cm CONT_MSTR_IDX01) */
TO_CHAR(regist_date, 'YYYYMMDD') td,... COUNT(1) as cnt
FROM mstr cm
WHERE ...AND cm.regist_date >= : LastDayOfMonth
GROUP BY TO_DATE(cm.regist_date, 'YYYYMMDD'), cm.category_id) a,
mstr_cate b
WHERE a.scode = b.scode ...
GROUP BY a.td;
코드 1. 최근 1개월 집계 SQL
그래서 RDBMS의 대안으로 검토한 것은 MapReduce 개념이었다. MapReduce는 RBDMS의 Sort/Merge 기능과 흡사하며, 대량의 데이터를 읽고 분석하는 OLAP분야의 일괄데이터 분석에 적합하다. 흔히 MapReduce 하면 Hadoop을 떠올리지만, MongoDB, HBase, CouchDB, Hypertable 등에서도 MapReduce 기능을 제공하고 있다. 그 중 사용자 층이 가장 두텁고 오랜 시간 검증된 Hadoop을 선정했고, 아울러 Document-oriented 방식으로 로그를 순차 저장하기 용이한 MongoDB 두 가지 솔루션을 테스트하고 검증하였다. Hadoop 기반의 MapReduce를 검증하기 위해서는, DBMS에 직접 접근할 수 없으므로 데이터 추출 작업이 선행되어야 한다. DBMS에 저장된 로그 데이터를 추출하기 위해, 오픈 소스 ETL(Extract, Trans- form, Load) 솔루션인 Pentaho의 Kettle을 사용하였다. (ETL은 Data warehousing 관련하여 자주 등장하는 용어). 본 테스트에서는 Hadoop의 여러 기능 중에서 HDFS 지원과 MapReduce Framework을 이용했다.
테스트를 위해 세가지 환경을 구성하였고, Hadoop의 경우 Standalone 모드와 3개의 DataNode와 1개의NameNode로 구성된 분산 모드에서의 성능 차이를 살펴보았다. 아울러 MongoDB의 MapReduce 성능비교도 수행하여 표 2와 그림 2으로 정리하였다. 참고로 테스트를 수행한 장비의 사양은 다음과 같다(본 테스트에 사용된 장비의 스펙은 모두 동일함).
- CPU : Intel(R) Xeon(R) CPU L5420@2.50GHz * 2 (8 cores)
- Memory : 32G
- Disk : 814G (300G * 6ea, RAID 0 + 1)
- OS : CentOS 5.2 x86_64
위 사양의 서버로 Hadoop Standalone 은 1대, 3 DataNode 환경은 총 4대, MongoDB 은 총 5대로 구성하였다(최종 시스템 구성은 뒤쪽의 그림 4 참조). Hadoop의 3 DataNode 환경은 NameNode와 DataNode를 분리한다. 그 이유는 메인 컨트롤러와Reduce 작업을 하는 Job Tracker는 NameNode에서 실행되고, 실제 Map 작업을 수행하는 Task Tracker는 DataNode 실행서버에서 실행되기 때문이다. MongoDB에 대한 자세한 설명은 뒤에서 하기로 하고, MapReduce를 Hadoop과 유사하게 사용할 수 있도록 기능을 제공한다는 정도만 밝힌다.
Hadoop의 3 DataNode 와 NameNode 등의 클러스터 구성도는 그림 3와 같고, 비교대상인 MongoDB 의 Shard 구성은 아래 그림 4을 참고 바란다.
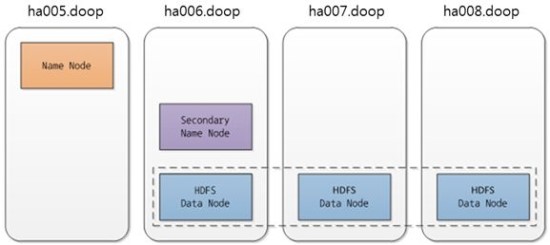
그림 2. Hadoop 클러스터 구성도
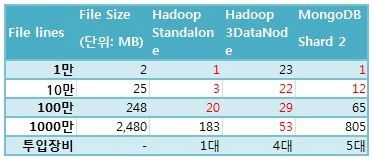
표 2. Hadoop vs. MongoDB MapReduce 성능비교
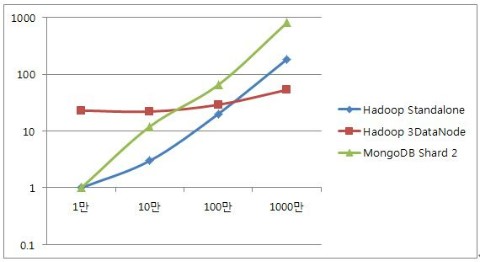
그림 3. Hadoop vs. MongoDB MapReduce 성능비교 (축은 Log scale)
표 2와 그림 3에서 알 수 있는 내용은 작은 양의 데이터에서는 Standalone 모드가, 많은 양의 데이터에서는 3 DataNode(n개의DataNode로 구성가능) 모드가 좋은 성능을 발휘한다는 것이다. 작은 양의 데이터를 3 DataNode에서 수행할 경우, Map Task가 각 DataNode에서 분산 수행되어 얻는 장점보다 Reduce Task가 NameNode에서 수행이 되어 설정과 네트워크 통신 시간이 필요하다는 단점이 더 부각되어 상대적으로 성능이 떨어진다. 본 테스트에서 활용한 시스템 구성과 데이터의 경우에는 병렬 수행의 장점이 발휘되는 1천만 Rows부터 3 DataNode 모드가 더 성능이 좋았다. 이는 Workload와 시스템의 성능에 따라 좌우가 되므로 적용 시에는 반드시 테스트가 필요할 것이다.
Standalone 테스트에는 장비 1대가 투입되었고 3 DataNode는 장비 4대가 들어갔기 때문에, 이에 대한 데이터 보정이 필요한 것은 사실이다. 하지만 Standalone 4대로 시스템을 구축할 경우에는 데이터 분할 및 취합의 과정이 별도로 필요하기 때문에, 개발 공수가 증가하는 side-effect가 있어서 더 자세한 고려를 하지 않았다. 또한 데이터가 증가하여 확장이 필요할 경우, Standalone모드에서는 분할 및 취합에 대한 변경 작업이 필요하지만, 분산 모드에서는 DataNode만 추가하는 것으로 자동 Striping이 되어 상대적으로 변경 작업이 간단하다는 장점도 있다.
Hadoop과 유사한 성능을 보인다면, MongoDB만으로도 집계시스템과 추출 지표 저장 시스템을 한방에(!) 구축할 수 있다는 기대에, MongoDB 테스트도 진행하였다. 위의 표 2에 MongoDB의 MapReduce 테스트 결과가 포함되어 있는데, 아쉽게도Hadoop에 비해서 성능이 많이 낮게 나왔다. Hadoop의 3 DataNode에 비해서 4배 정도는 느리다고 볼 수 있다.
테스트가 끝날 당시 MongoDB 1.8 버전이 릴리즈 되어 위 테스트 결과는 무의미해졌지만, 위 결과에서 크게 바뀌지는 않으리라 생각한다. 우리 팀은 1.6.5 버전으로 테스트를 진행하고 구축하였고, 현재 진행 중인 업그레이드 작업이 완료되면 1.8 버전으로도 성능을 테스트하여 공유하겠다.
MongoDB의 장점은 개발 생산성
작은 양의 데이터를 사용할 경우에는 여전히 MongoDB가 유용하다. 성능에서 보여준 단점을, 개발 생산성의 장점으로 만회할 수 있기 때문이다. 아래의 코드 2는 Hadoop의 Java API를 이용한 MapReduce method이고, 코드 3에 MongoDB의 MapReduce내장 Command이다. 두 코드를 비교해 보면 MongoDB Command가 월등히 단순하다. 코드를 보면 확인할 수 있겠지만, MongoDB의 command는 Scalar나 Ruby 같은 Functional Language의 장점을 채용하고 있기 때문이다. 물론 Hadoop도 파이썬 등의 스크립트 언어를 이용하면 좀더 효율적으로 작성 할 수 있다.
//Map
public static class DailyIdCountMapClass extends MapReduceBase implements
Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter)throws IOException {
String line = value.toString();
String[] tokens = line.split(UserIdConstants.COLUMN_SEPARATOR);
String userKey = tokens[0];
output.collect(new Text(userKey), new IntWritable(1));
}
}
//Reduce
public static class DailyIdCountReduceClass extends MapReduceBase implements
Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
<이하생략>
코드 2. Hadoop MapReduce Java API source code
> m = function() { emit(this.user_id, 1); }//Map
> r = function(k,vals) { return 1; }//Reduce
> res = db.wklog_user.mapReduce(m, r);
코드 3. MongoDB MapReduce command
Hadoop의 MapReduce 기능은 성능 면에서는 우위였지만, Map function의 Debug를 위한 메시지가 분산된 DataNode에서 출력되기 때문에 디버깅은 쉽지 않다. 코드를 작성하고, 컴파일과 함께 jar 아카이브를 생성하고 실행하는 단계를 거치므로, 유지 보수 작업도 번거로운 편이다. 대신 기본개념만 잘 이해했다면 MapReduce function을 작성하는 것은 어려움이 없어 코딩은 쉽다고 할 수 있다. 추가로 상세한 파라미터 등의 튜닝이 필요하지만, 이는 본 기사의 범위를 벗어나 생략한다.
데이터 집계 테스트는 RDBMS와, Hadoop Standalone, Hadoop 3DataNode, MongoDB의 MapReduce 등 4가지를 비교하는 것으로 진행하여, Hadoop을 n개의 DataNode로 구성하는 것으로 결론이 났다. 상대적인 빠른 속도와 간편하게 확장이 가능하다는 점에서 비교 우위를 보였기 때문이다.
집계정보 저장소 선정 MongoDB vs. Cassandra
지금까지 기존 RDBMS의 Group by 연산을 MapReduce Framework 로 대체하기 위한 테스트를 수행하였다. 이제 이러한 집계작업의 결과데이터를 저장, 관리, 제공 역할을 할 저장소 테스트를 수행할 차례이다. 스토리지 증가의 제약 때문에 RBDMS는 처음부터 배제하고 시작하였다. 테스트 대상은 전세계적으로 널리 사용되고 사용자 층이 두터운 두 가지를 선택하였다. 첫 번째 벤치마크 대상은 Facebook에서 개발하여 유명한 Column family 유형의 Cassandra이다(최근 기사를 보면 Facebook은HBase를 이용하여 200억/daily 이벤트에 대한 실시간 분석 시스템을 구축하였다. HBase를 MapReduce 및 저장소로 사용한 것이다. HBase를 벤치마크 대상에 넣지 못한 것이 아쉽게 느껴진다). 두 번째 대상은 Hadoop과 MapReduce 성능비교를 했던MongoDB이다. MongoDB는 직관적인 Document-oriented 방식의 데이터 모델이고, Schema-Free의 장점으로 유연한 필드관리가 가능하다. 아울러 Full-Text 인덱싱을 지원함으로써 모든 Document내 필드에 빠른 검색을 제공하며, 특정 필드들로Index를 Build할 수도 있다. C++로 개발된 MongoDB는 성능 및 안정성 면에서도 좋은 평가를 받고 있다.
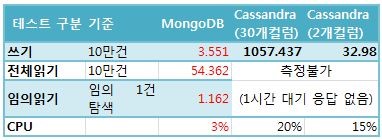
표 3.
MongoDB vs. Cassandra 쓰기/읽기 성능비교표-3를 보면 Cassandra 의 쓰기 성능이 MongoDB에 비해 많이 나쁜 것이 것이 눈에 띈다. 작성된 코드와 문서를 검토한 결과,두 솔루션의 철학 차이가 성능의 차이를 나타냈다고 볼 수 있다. MongoDB는 Document-oriented이기 때문에, DB의 1 row에 해당하는 단위를 단 한번의 document insert 작업으로 처리한다. 반면에 Cassandra는 Column-base이기 때문에 row가 아닌column 단위의 insert가 수행되고, 그만큼 수행 시간이 늘어날 수 밖에 없다. 위 테스트에서 사용한 데이터의 경우 30개의 컬럼으로 이루어졌으로, 단순 비교를 하여도 약 30배에 가까운 수행 시간이 걸릴 것이다. 하지만 실제 성능 테스트 데이터는 300배 정도의 성능 차이를 보였다. 아래의 코드 4는 컬럼의 개수만큼 반복하여 insert 작업을 수행해야 한다는 것을 보여준다.
ColumnPath columnPath1 = new ColumnPath(columnFamily);
columnPath1.setColumn(columnName1.getBytes());
client.insert("Keyspace1", key, columnPath1, columnValue1.getBytes(),timestamp, ConsistencyLevel.ONE);
<중략>
ColumnPath columnPathN = new ColumnPath(columnFamily);
columnPathN.setColumn(columnNameN.getBytes());
client.insert("Keyspace1", key, columnPathN, columnValueN.getBytes(), timestamp, ConsistencyLevel.ONE);
코드 4. Cassandra Insert sample
정말 컬럼 단위의 insert가 쓰기 성능에 영향을 미친 것인지 검증을 하기 위해, 컬럼 수를 줄여 간단한 테스트로 접근해 보았다. Key 컬럼을 제외한 나머지를 단일 컬럼으로 결합하여 2개 컬럼으로 줄인 후 수행하였다. 표 2의 마지막 열을 보면 10만건 쓰기에30초대로 많이 향상되었지만, 그래도 MongoDB의 쓰기성능을 앞지르진 못했다.
참고로 Cassandra 성능 테스트에 사용된 스키마 구조는 자유롭게 컬럼을 구성하여 하나의 Key와 관련된 모든 집계정보를 담고자 설계하였다. 다층 구조로 설계하여 계층별로 데이터 항목을 추가 하기 쉽도록 한 것이다. 스키마를 설계할 당시엔 가변적인 스키마 설계에 더할 나위 없이 좋아 보여 쾌재를 부렸지만, 테스트결과 성능이 좋지 않아 아쉽게 폐기되었다.
|
|
Cassandra에서 제공하는 분산 노드 기능을 사용하면 동일 Key 읽기 성능이 지금보다는 좋을 수 있겠지만, n개의 node구성을 고려한 테스트는 내부적인 사정으로 이번 테스트 범위에서는 제외되었다. 따라서 동일한 비교를 위해 MongoDB 역시 단일 노드로 구성하여 테스트하였다.
참고로 MongoDB는 저장 엔진의 오류복구와 내구성을 위해 write-ahead 저널링을 1.7.5부터 지원하고 있으며, 이 저널링 옵션을 사용한다면, 안정성이 올라가는 대신 MongoDB의 측정 결과도 더 나쁜 수치로 변할 수 밖에 없지만 이 부분 역시 이번 테스트 범위에서는 제외되었다. 집계 데이터의 특성상 복구가 용이하기 때문이다.
위의 테스트 결과와는 별도로, MongoDB에서 결합 index 기능을 제공하는 것도 선정의 중요한 이유가 되었다. 집계 데이터에 대한 여러 조회 조건을 활용하기 위해 복수의 Index 설정이 필요하다. MongoDB는 100만건 정도 데이터에 대한 index를 1초 내외로 Build할 수 있다. 또한 관계형 데이터베이스에 익숙한 사용자라면 기존의 SQL을 사용하는 것과 개념적으로 유사하여 좀더 쉽게 접근할 수 있다. 반면 Cassandra는 key-value 기반의 트리 구조에 대한 이해가 선행 되어야 한다는 차이가 있다. 여기를 보면 SQL과 MongoDB Statement를 매핑하여 설명하고 있다.
MongoDB와 Cassandra의 성능테스트에서는 우리에게 필요한 일괄 쓰기 성능과 여러 컬럼에 대한 읽기 성능 면을 고려하여MongoDB를 선정하였다. 읽기/쓰기 성능테스트는 Standalone으로 테스트를 수행했지만, MongoDB의 최종 구성은 그림 4과 같이 서버 5대로 구성하였다.
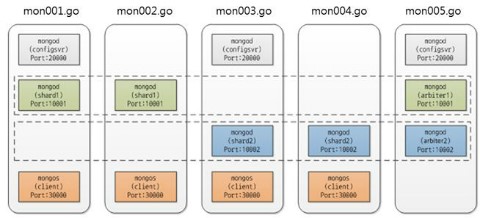
그림 4. MongoDB 클러스터 구성도
그림 4과 같이 구성하면서 2가지의 시행착오를 경험하였다. 첫 번째 mongod config server 개수를 arbiter 서버를 제외하고 4대로 설정했다가 서버가 동작하지 않아 고생을 했다. 설정 문서에 “1대 또는 3대로 구성하라”고 기술되어 있는데, 이를 놓친 것이다.또한, 네트워크 장애상황에서 여러 서버에 걸쳐있는 shard 구성이 오작동 하여, 데이터 정합성을 유지하지 못할 수 있다. 이를 해결하기 위해 반드시 별도의 arbiter 서버(그림 4의 mon005.go)를 설정하기 바란다.
최종 Hadoop & MongoDB 기반 집계 시스템
그림 5이 최종적으로 구성된 시스템 구성도이다. 단일 Hadoop 서버와 단일 MongoDB로 구성할 수도 있겠지만, 지속적으로 데이터가 증가하는 시스템의 특성상 이 기회에 Scale-Out이 가능하도록 구축을 하였다. RBDMS – ETL – Hadoop – MongoDB로 데이터가 흐르는 구성이다.
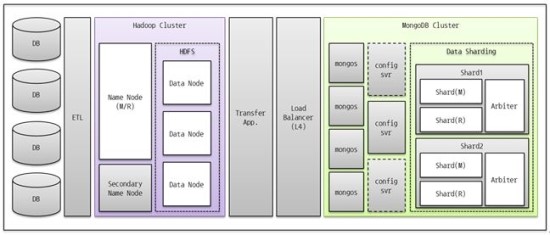
그림 5. Hadoop & MongoDB 기반 집계분석 시스템 구성도
그림 5의 동작 시나리오를 요약하면 다음과 같다.
1) DB에서 집계해야 하는 대상 데이터를 선정
2) ETL툴을 이용하여 데이터를 추출
3) Hadoop Cluster의 HDFS DataNode에 분산 적재
4) Hadoop Cluster의 NameNode에서 MapReduce 수행
5) Transfer Application 을 이용하여 집계결과를 MongoDB에 전송 및 적재되며,
이 때 Load Balancing을 위해 L4를 둔다
6) MongoDB에 적재된 데이터는 외부 모듈에 의해 사용자에게 서비스 된다
위 항목 1)에서 3)까지는 자연스러운 데이터의 흐름이며, 4)에서 MapReduce로 집계업무가 수행된다. 항목 5)에서 MongoDB로의 접근은 L4를 통하여 부하가 분산 되도록 하는 것이 좋으며, Client작성시 서버목록(mongos Server List)을 기술할 수도 있다.또는 RequestBroker를 활용하는 것도 가능하리라 생각하는데, 이 부분은 곧 검증을 진행할 예정이다. 5)에서는 MongoDB가 제공하는 API를 통해 집계결과를 저장한다. 1)에서 5)까지의 과정이 완료되면 사용자에게 데이터 제공이 가능한 상태가 된다. 항목6) MongoDB에 저장되는 프로세스를 보충 설명 하면, 클라이언트 서버에서 config 서버를 통해 어느 shard(분산된 저장소를 의미함)에 저장될 것인지 결정된다. shard 내의 Master 서버에 저장 된 후 Replication 서버로 복제된다. MongoDB는 Arbiter를 지정하여 분산된 서버들 중 오류가 발생한 서버가 있을 때 남은 서버 중 Master 서버를 선출할 수 있도록 해야 한다.
마치며
위의 시스템을 구성하는 것으로 1차 목표는 달성을 하였다. 향후 MapReduce나 NoSQL 솔루션을 도입하고자 하는 부서는 다음을 고려하면 좋겠다. MapReduce를 적용하고자 하는 경우라면, 데이터 건수가 작은 경우는 Hadoop Standalone, 많은 경우는3개 이상의 DataNode로 구성하는 것이 적절하다. 단, 이미 MongoDB를 사용하고 있고, 건수가 많지 않은 경우라면 MongoDB의MapReduce도 유용할 것이다.
NoSQL의 경우, 다중 Index가 필요한 구조라면 MongoDB를 선택하고, 데이터 항목 변경이 많고 unique access가 많은 경우라면 Cassandra가 맞는다 생각한다. 물론 아직 HBase 등을 테스트 해보지 않았으므로, 이에 대한 추가 검토가 있으면 더 좋겠다.
1차 목표 후, 2차에 대한 고민도 진행하고 있다. 지속적으로 늘어나는 RBDMS의 데이터를 효과적으로 처리할 수 있는 장기대책 마련이다. 마스터 데이터에 대한 결합도가 낮고, 조회 빈도 역시 낮은 로그 성격의 데이터를 NoSQL 저장소로 이동하는 것이다.이 문제를 NoSQL 솔루션으로 해결하면, 상대적으로 고비용인 RDBMS스토리지를 절감할 수 있을 것으로 기대한다.
NoSQL 솔루션은 매우 다양한 요구에 의해 발전하고 있고, http://nosql-database.org/에 잘 소개되어 있으니 참고하기 바란다.필자가 경험한 NoSQL의 가장 큰 장점은 “Scale-Out”이 아닐까 생각한다. 여기에 상대적으로 빠른 쓰기/읽기 성능은 보너스이다. 대신 잃을 수 있는 것은 “개발자의 주옥 같은 여가시간”이다.
생생하게 NoSQL 적용 사례를 공유하고 싶었고, 우리가 고민한 여러 가지 이야기가 다른 개발팀에도 도움이 되길 바라는 마음이다. 처음 써보는 기사인데다 부족한 글 솜씨가 팀원들의 고생에 누가 되지 않을까 걱정이 앞선다.
최근 NoSql제품의 실무적용이 많이 늘고 있어 더 많은 자료가 공유되길 기대해 본다.
참고자료
[1] Hadoop완벽가이드,한빛미디어
[2] 클라우드컴퓨팅구현기술, 에이콘
[3] The Platform 2010년 10월호 “NoSQL을 여행하는 히치하이커를 위한 안내서, NoSQL어디에쓰는가”
[4] http://www.mongodb.org/display/DOCSKR/
[6] http://blog.nahurst.com/visual-guide-to-nosql-systems
[7] http://www.infoq.com/articles/nosql-in-the-enterprise
[9] http://www.rackspace.com/cloud/blog/2009/11/09/nosql-ecosystem/
작성일자 2011.07.25
작성자 NHN Technology Services 웹서비스개발실 이정현 실장